

Neste artigo eu quero mostrar como nós podemos manipular uma Delta table usando um notebook do Microsoft Fabric com Python, não PySpark.
Todos notebooks no Microsoft Fabric iniciam por padrão com PySpark, mas nem todos os projetos precisam rodar com PySpark. Nós podemos rodar com Python puro.
Analisando a documentação no Microsoft Learn, nós podemos ver como escolher entre Python e PySpark baseand-se nas recomendações de uso. Abaixo, eu trago a matriz de decisão rápida que resume qual abaordagem é mais apropriada.
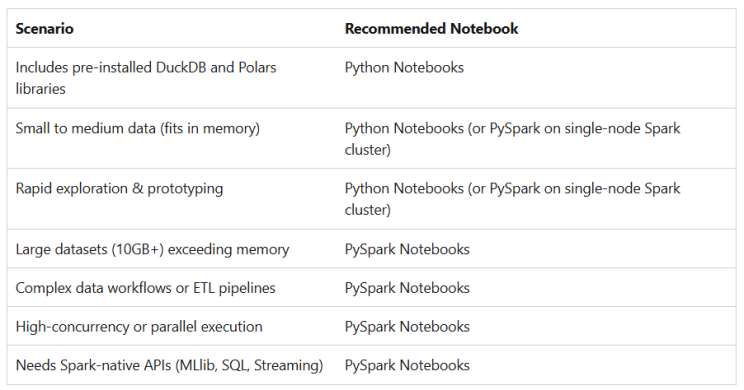
Como podemos ver, PySpark é melhor para grandes conjuntos de dados e comples cenários onde você pode tirar vantagens da computação distribuída.
No entanto, em muitos casos de uso do mundo real, os conjuntos de dados são de pequeno a médio porte e podem ser processados de forma eficiente usando Python puro, o que ajuda a otimizar o consumo de Capacity Units e até mesmo evitar possíveis problemas ao trabalhar com conjuntos de dados muito pequenos.
Atualmente, percebo que a maioria das discussões sobre notebooks no Microsoft Fabric se concentra fortemente no PySpark, enquanto o Python puro ainda é pouco explorado nesse contexto.
De fato, se você quiser usar Python puro para manipular tabelas Delta em um Lakehouse, será necessário adotar padrões de código diferentes em comparação com a abordagem em PySpark.
Pensando nisso, decidi compartilhar um notebook de exemplo no meu GitHub para ajudar você a começar e otimizar seus notebooks no Fabric utilizando Python puro.
Na seção a seguir, vou apresentar as principais partes do código, trazendo insights que você pode adaptar aos seus próprios processos.
A primeira célula apenas importa as bilbiotecas necessárias para executar o notebook.
Talvez você nunca dee ter escutado antes falar sobre a bilbioteca deltalake. Confira a documentação para compreensão de todas as funções: Delta Lake Documentation
import notebookutils
import pandas as pd
import pyarrow as pa
from deltalake import write_deltalake, DeltaTable
from sempy.fabric import get_notebook_workspace_id, list_workspacesEsta célula representa minha preferida maneira de trabalhar com notebooks e lakehouses. Eu intencionalmente não conecto nenhum lakehouse ao notebook, pois esta abordagem simplifica muito os pipelines de CI/CD. Ao invés disso, eu dinamicamente busco o nome e ID do workspace e construo o endereço ABFSS dinamicamente.
workspace_id = get_notebook_workspace_id()
workspace_name = list_workspaces().query("Id == @workspace_id")['Name'].iloc[0]
lakehouse_name = 'Lakehouse'
lakehouse_path = (f'abfss://{workspace_name}@onelake.dfs.fabric.microsoft.com/'
f'{lakehouse_name}.Lakehouse')
tables_path = f'{lakehouse_path}/Tables'
table_name = 'Transactions'
table_path = tables_path + '/' + table_name
print(f'Workspace: {workspace_name} | ID: {workspace_id}')
print(f'Tables path: {tables_path}')
print(f'Table path for this example: {table_path}') Workspace: Playground | ID: 985b1e03-58a6-4bde-a4da-91df29399350
Tables path: abfss://Playground@onelake.dfs.fabric.microsoft.com/Lakehouse.Lakehouse/Tables
Table path for this example: abfss://Playground@onelake.dfs.fabric.microsoft.com/Lakehouse.Lakehouse/Tables/Transactions Com alguns dados de exemplo eu crio um pandas.DataFrame e escrevo uma tabela Delta no lakehouse.
Na mesma célula eu recupero os dados carregados e mostro na saída.
# Sample data
records = [
(1, '2025-08-01', 1234.56),
(2, '2025-08-02', 2345.67),
(3, '2025-08-03', 3456.78)
]
# Create the pandas.DataFrame
df = pd.DataFrame.from_records(records, columns=['ID', 'Date', 'Amount'])
# Force the column types
df['ID'] = df['ID'].astype('int64')
df['Date'] = pd.to_datetime(df['Date']).dt.date
df['Amount'] = df['Amount'].astype('float64')
# Write the DeltaTable with overwrite mode
write_deltalake(table_path, df, mode='overwrite')
# Read back to verify
dt = DeltaTable(table_path)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
# Converts col Date to datetime
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID')) 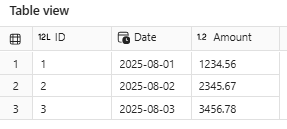
Nesta célula, eu demonstro como acrescentar novas linhas na tabela Delta. Simples, não?
# New sample rows
records = [
(4, '2025-08-04', 4567.89),
(5, '2025-08-05', 5678.90),
(6, '2025-08-06', 6789.01)
]
# Create the pandas.DataFrame
df = pd.DataFrame.from_records(records, columns=['ID', 'Date', 'Amount'])
# Force the column types
df['ID'] = df['ID'].astype('int64')
df['Date'] = pd.to_datetime(df['Date']).dt.date
df['Amount'] = df['Amount'].astype('float64')
# Write the DeltaTable with append mode
write_deltalake(table_path, df, mode="append")
# Read back to verify
dt = DeltaTable(table_path)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
# Converts col Date to datetime
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID')) 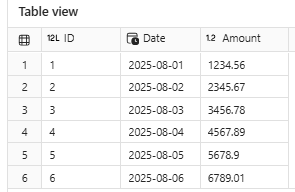
Neste exemplo, eu demonstro como deletar linhas de uma tabela Delta.
Repare que a condição de deleção usa o padrão da cláusula WHERE do SQL.
dt = DeltaTable(table_path)
dt.delete('ID IN (4, 5, 6)')
# Other Examples
# dt.delete('ID IS NULL')
# dt.delete("Date BETWEEN '2025-08-07' AND '2025-08-31'")
# Read back to verify
dt = DeltaTable(table_path)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
# Converts col Date to datetime
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID')) 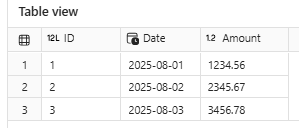
Esse exemplo traz um caso um pouco mais compleso, mas muito comum – executar a operação de MERGE usando o padrão UPSERT, o qual é extremamente útil para atualizações incrementais.
dt = DeltaTable(table_path)
dt.delete('ID IN (4, 5, 6)')
# Other Examples
# dt.delete('ID IS NULL')
# dt.delete("Date BETWEEN '2025-08-07' AND '2025-08-31'")
# Read back to verify
dt = DeltaTable(table_path)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
# Converts col Date to datetime
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID'))
Output:
Maximize image
Edit image
Delete image
Add a caption (optional)
Merging data with with DeltaTable
This example brings a more complex use case — performing a Merge operation using an Upsert pattern, which is extremely useful for implementing incremental data refreshes.
# Sample data to perform a merge
records = [
(1, '2025-08-04', 9876.54),
(2, '2025-08-05', 8765.43),
(3, '2025-08-06', 7654.32),
(4, '2025-08-07', 6543.21)
]
# Create the pandas.DataFrame
df = pd.DataFrame.from_records(records, columns=['ID', 'Date', 'Amount'])
# Force the column types
df['ID'] = df['ID'].astype('int64')
df['Date'] = pd.to_datetime(df['Date']).dt.date
df['Amount'] = df['Amount'].astype('float64')
# Transform from pandas.DataFrame to pyarrow.Table
source_data = pa.Table.from_pandas(df)
# Reading the target_data
dt = DeltaTable(table_path)
target_data = dt.to_pyarrow_dataset().to_table()
# Execute the merge
(
dt.merge(
source=source_data,
predicate="target.ID = source.ID",
source_alias="source",
target_alias="target")
.when_matched_update(
updates={
"Date": "source.Date",
"Amount": "source.Amount"
})
.when_not_matched_insert(
updates={
"ID": "source.ID",
"Date": "source.Date",
"Amount": "source.Amount"
})
.execute()
)
# Read back to verify
dt = DeltaTable(table_path)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
# Converts col Date to datetime
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID')) 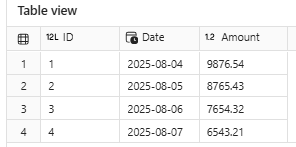
Um recurso poderoso do Delta Lake é a capacidade de rastrear todo o histórico de operações realizadas em uma tabela. Ao chamar o método history() em um objeto DeltaTable, você pode acessar metadados sobre cada transação — incluindo timestamps (data/hora), tipos de operação (por exemplo, write, merge, delete), o número de linhas afetadas e a versão do engine utilizada.
Essa funcionalidade é especialmente útil para:
• Auditar alterações nos dados
• Depurar operações de merge/upsert
• Entender o ciclo de vida da sua tabela
Aqui está um exemplo rápido:
dt=DeltaTable(table_path)
history = pd.DataFrame(dt.history())
display(history) 
O Delta Lake permite que você leia uma versão específica da tabela utilizando o parâmetro version. Isso é útil para time travel, depuração ou para reproduzir resultados a partir de um estado passado da tabela.
dt = DeltaTable(table_path, version=0)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID')) 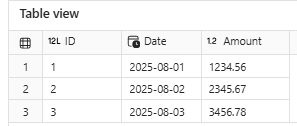
dt = DeltaTable(table_path, version=3)
df_loaded = dt.to_pyarrow_dataset().to_table().to_pandas()
df_loaded['Date'] = pd.to_datetime(df_loaded['Date'])
display(df_loaded.sort_values('ID')) 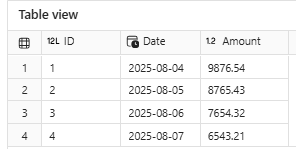
Os exemplos compartilhados aqui são funções básicas, com fins demonstrativos. Recomendo fortemente que você vá além da leitura — a melhor forma de aprender é colocando a mão na massa e incorporando código real aos seus próprios processos.
Existem muitos outros recursos poderosos do Delta Lake que valem a pena explorar, como VACUUM, Z-ORDER e OPTIMIZE, que podem melhorar significativamente o desempenho e a eficiência de armazenamento em ambientes de produção.
Utilizar Python puro em notebooks do Microsoft Fabric pode ajudar a otimizar o consumo de Capacity Units e evitar sobrecarga desnecessária ou complicações relacionadas ao PySpark — especialmente em cenários de microprocessamento.
Por isso, é tão importante avaliar cada projeto individualmente, considerando sua escala, complexidade e restrições de recursos antes de escolher a abordagem de implementação.
Espero que este artigo ajude você a repensar como estruturar seus notebooks no Microsoft Fabric — equilibrando desempenho, simplicidade e manutenibilidade.
Fique à vontade para compartilhar sua opinião nos comentários ou entrar em contato. Vamos continuar construindo soluções melhores — uma célula por vez. 🚀
Full notebook: microsoft-fabric-notebook-python-ex-001/Notebook.ipynb at main · alisonpezzott/microsoft-fabric-notebook-python-ex-001
Choosing Between Python and PySpark Notebooks in Microsoft Fabric
Deltalake python lib docs: Home – Delta Lake Documentation