

Neste vídeo e artigo demonstro como utilizar a vista do lago materializada do Microsoft Fabric.
Este recurso ainda em Preview (janeiro de 2026) é um recurso disruptivo no Microsoft Fabric quando falamos em ingestão e tratamento entre camadas do Lakehouse.
Uma view SQL (visão, vista) tradicional nada mais é do que uma query, uma instrução que foi salva.
Contudo uma vista (ou view) não possui dados. Ou seja, não é possível inserir, atualizar ou excluir dados de uma view. O resultado de uma view é obtido quando requisitamos os dados desta view seja dentro do banco de dados ou pipelines de atualização de processos de ingestão de dados, seja qual for
Utilizar uma view em muito dos casos pode mascarar queries ruins fazendo com que o processo de ingestão/transformação perca performance.
Views materializadas já existem em alguns bancos de dados, como no Postgres por exemplo.
Materializar uma view é basicamente a ação de popular com dados uma tabela com o resultado de uma view. Isto é o que está sendo proposto no Microsoft Fabric com as MLV`s ou materialized lake views ou usando ao pé da letra a tradução da documentação, vistas do lago materializadas.
Para que este recurso seja testado criei um material de apoio para que você possa reproduzir os mesmos passos demonstrados no vídeo citada acima e disponível aqui.
Faça o download dos arquivos e extraia em sua pasta Downloads
Baixe aqui
Crie um novo workspace chamado de demo_mlv no Microsoft Fabric e configure uma capacidade do Fabric (Malha ou Trial).
Clique em novo item e crie o lakehouse chamado lh_lakehouse. Habilite a caixa Lakehouse schemas
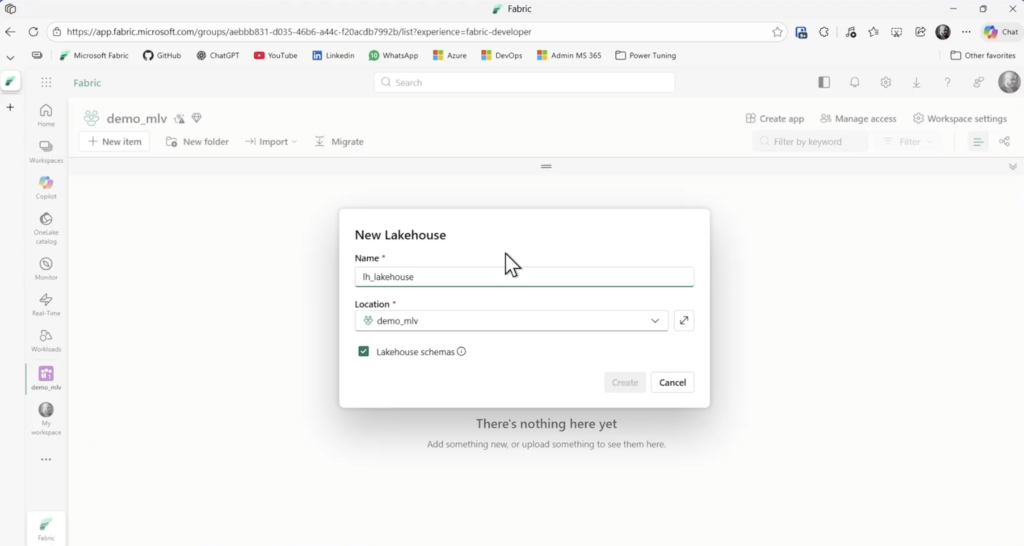
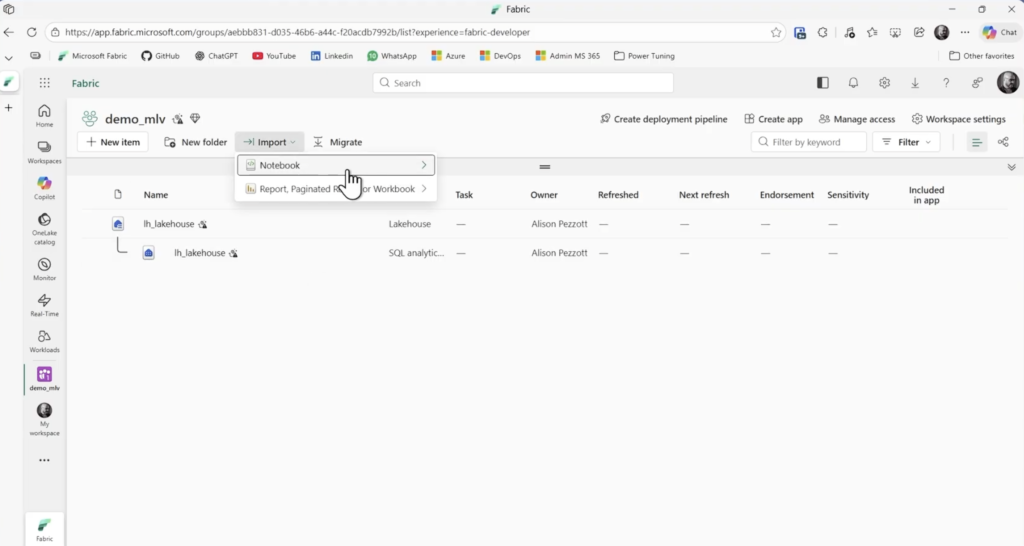
Depois vá até Import/Notebook e carregue os notebooks dentro da pasta scripts do zip baixado. Arquivos *.ipynb
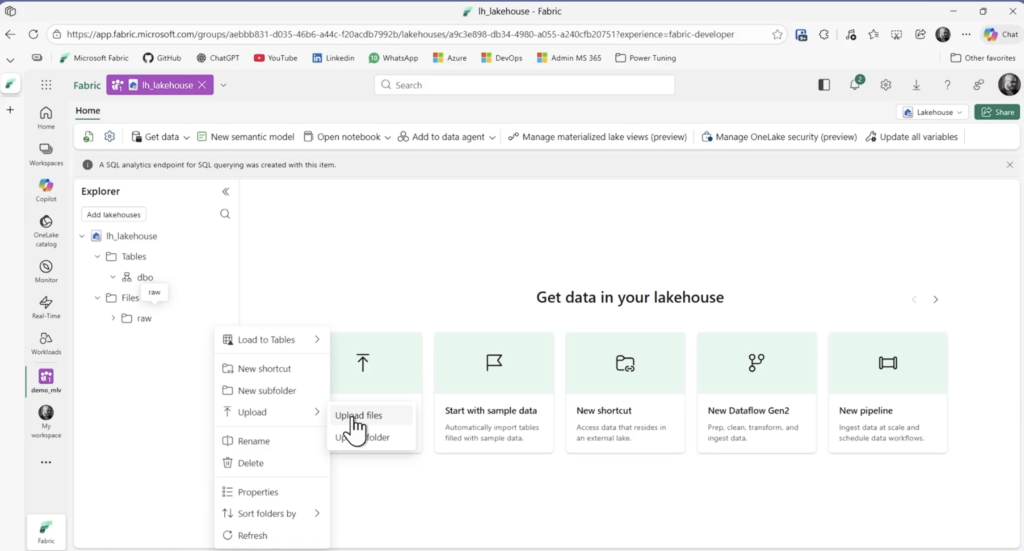
Após importar os notebooks, abra o lakehouse e crie uma subpasta chamada raw dentro de Files clicando nos três pontinhos.
Clicando novamente nos três pontinhos escolha Upload / Upload Files e importe todos os arquivos contidos na pasta data do zip baixado.
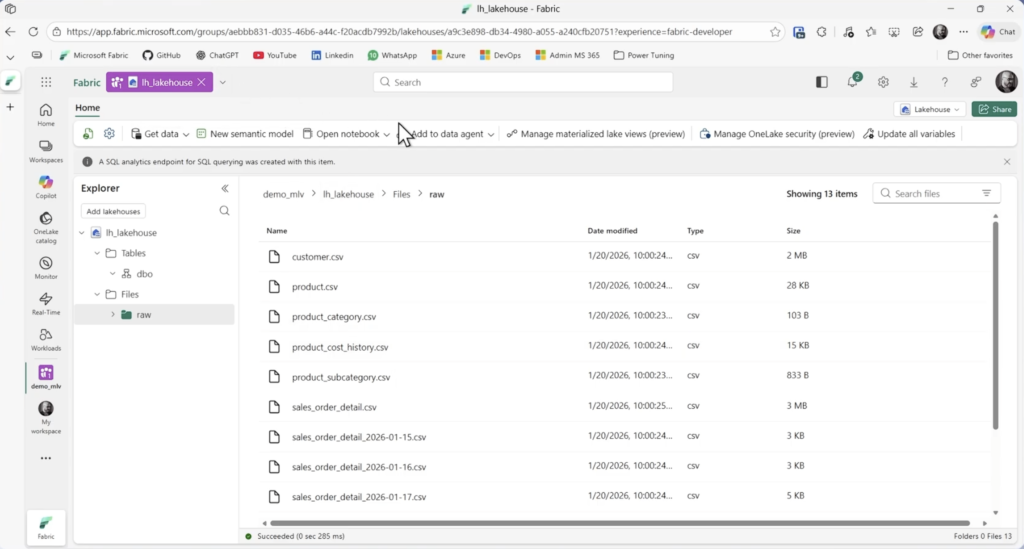
De dentro do lakehouse, clique em abrir o notebook e escolha o nb_01_import_first_data
Abaixo segue o código do notebook PySpark
Nesta célula estamos importando os tipos de dados par ainferir o schema para ler corretamente os arquivos *.csv
from pyspark.sql.types import (
StructType, StructField, IntegerType, StringType,
DateType, DoubleType, ShortType, DecimalType
)
Com o magic cria-se o schema bronze para as tabelas Delta
%%sql
CREATE SCHEMA IF NOT EXISTS bronzePara cada tabela Delta será criado o schema com os nomes das colunas e tipos de dados. Cada arquivo csv é carregado.
# product
schema = StructType([
StructField("product_id", IntegerType(), False),
StructField("product_subcategory_id", IntegerType(), True),
StructField("product", StringType(), False),
StructField("color", StringType(), True),
StructField("size", StringType(), True),
StructField("product_line", StringType(), True),
StructField("class", StringType(), True),
StructField("style", StringType(), True),
StructField("product_model_id", IntegerType(), True),
])
df = (spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/product.csv"))
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.product")# product_category
schema = StructType([
StructField("product_category_id", IntegerType(), False),
StructField("product_category", StringType(), False),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/product_category.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.product_category")# product_subcategory
schema = StructType([
StructField("product_subcategory_id", IntegerType(), False),
StructField("product_category_id", IntegerType(), False),
StructField("product_subcategory", StringType(), False),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/product_subcategory.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.product_subcategory")# product_subcategory
schema = StructType([
StructField("product_subcategory_id", IntegerType(), False),
StructField("product_category_id", IntegerType(), False),
StructField("product_subcategory", StringType(), False),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/product_subcategory.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.product_subcategory")
# customer
schema = StructType([
StructField("customer_id", IntegerType(), False),
StructField("first_name", StringType(), False),
StructField("middle_name", StringType(), True),
StructField("last_name", StringType(), False),
StructField("address_line_1", StringType(), False),
StructField("addess_line_2", StringType(), True),
StructField("city", StringType(), False),
StructField("state_province_code", StringType(), False),
StructField("country_region_code", StringType(), False),
StructField("state_name", StringType(), False),
StructField("territory_name", StringType(), False),
StructField("territory_group", StringType(), False),
StructField("start_date", DateType(), True),
StructField("end_date", DateType(), True),
StructField("is_active", IntegerType(), False)
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/customer.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.customer")# sales_order_detail
schema = StructType([
StructField("sales_order_id", IntegerType(), True),
StructField("sales_order_detail_id", IntegerType(), True),
StructField("sales_detail_item", IntegerType(), True),
StructField("items_per_order", IntegerType(), True),
StructField("order_qty", ShortType(), True),
StructField("product_id", IntegerType(), True),
StructField("unit_price", DecimalType(19, 4), True),
StructField("percentage_discount", DecimalType(19, 4), True),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/sales_order_detail.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.sales_order_detail")# sales_order_header
schema = StructType([
StructField("sales_order_id", IntegerType(), False),
StructField("order_date", DateType(), True),
StructField("ship_date", DateType(), True),
StructField("due_date", DateType(), True),
StructField("customer_id", IntegerType(), False),
StructField("tax_amount", DecimalType(19, 4), False),
StructField("freight", DecimalType(19, 4), False),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/sales_order_header.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.sales_order_header")# product_cost_history
schema = StructType([
StructField("product_id", IntegerType(), False),
StructField("start_date", DateType(), False),
StructField("end_date", DateType(), True),
StructField("is_active", IntegerType(), False),
StructField("standard_cost", DecimalType(19, 4), False)
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load("Files/raw/product_cost_history.csv")
)
df.write \
.mode("overwrite") \
.option("overwriteSchema", True) \
.saveAsTable("bronze.product_cost_history")O código a seguir aplica CDF para todas as tabelas do schema bronze. O CDF é a abreviação de Change Data Feed recomendado na documentação para otimizar os processos das vistas do lago materializadas.
Fonte: Refresh Materialized Lake Views in a Lakehouse – Microsoft Fabric | Microsoft Learn
# Apply CDF (Change Data Feed) to all table of the schema
schema = "bronze"
tbls = (
spark.sql(f"SHOW TABLES IN {schema}")
.select("tableName")
.collect()
)
for r in tbls:
t = f"{schema}.{r['tableName']}"
spark.sql(f"""
ALTER TABLE {t}
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
""")
A célula a seguir também aplica o Change Data Feed utilizado SQL. Ela está congelada no notebook fornecido. Apenas quis demonstrar caso for útil para outras situações.
%%sql
-- Option with SQL
ALTER TABLE bronze.customer
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
ALTER TABLE bronze.product
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
ALTER TABLE bronze.product_category
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
ALTER TABLE bronze.product_subcategory
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
ALTER TABLE bronze.sales_order_detail
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
ALTER TABLE bronze.sales_order_header
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
ALTER TABLE bronze.product_cost_history
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
Execute o notebook clicando em Run All.
Feito isto a primeira carga de dados será feito para a camada bronze.
Acessando o Lakehouse, clique em Manage materialized lake views.
E na sequencia acesse o notebook existente nb_02_materialized_lake_views
Ele que irá criar cada uma das vistas materializadas no lakehouse. Segue o código abaixo de cada MLV criada como um exemplo didático. Repare que aqui é utilizado exclusivamente SQL para criamos as MLVs que estão simulando nossas camadas Silver e Gold.
Cria-se o schema silver e gold.
CREATE SCHEMA IF NOT EXISTS silver;
CREATE SCHEMA IF NOT EXISTS gold;Inicia-se a criação das MLVs.
DROP MATERIALIZED LAKE VIEW IF EXISTS silver.customer;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS silver.customer
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
WITH cte_countries AS (
SELECT
DISTINCT country_region_code,
territory_group,
territory_name,
CASE
WHEN country_region_code IN ('AU', 'DE', 'ENG', 'FR', 'GB') THEN territory_name
WHEN country_region_code IN ('17', '31', '41', '45','57', '59', '62', '75', '77',
'78', '80', '91', '92', '93', '94', '95', 'BC', 'NSW', 'QLD', 'VIC' ) THEN territory_group
WHEN country_region_code = 'CA' AND territory_name = 'Canada' THEN 'Canada'
WHEN country_region_code = 'CA' AND territory_name = 'California' THEN 'United States of America'
WHEN country_region_code IN ('US', 'WA') THEN 'United States of America'
ELSE 'Undefined'
END AS country
FROM bronze.customer
)
SELECT
DISTINCT cu.customer_id,
CONCAT_WS(' ', cu.first_name, cu.middle_name, cu.last_name) AS customer_name,
CONCAT_WS(' ', cu.address_line_1, cu.addess_line_2) AS address,
cu.city,
cu.state_name AS state,
ct.country,
CONCAT_WS(
', ',
CONCAT_WS(' ', cu.address_line_1, cu.addess_line_2),
cu.city,
cu.state_name,
ct.country
) AS full_address,
cu.start_date,
cu.end_date,
cu.is_active
FROM bronze.customer cu
JOIN cte_countries ct
ON ct.country_region_code = cu.country_region_code AND
ct.territory_group = cu.territory_group AND
ct.territory_name = cu.territory_nameDROP MATERIALIZED LAKE VIEW IF EXISTS silver.product;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS silver.product
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT
p.product_id,
p.product,
s.product_subcategory,
c.product_category,
p.color,
p.size,
p.product_line,
p.class,
p.style,
p.product_model_id
FROM bronze.product p
JOIN bronze.product_subcategory s
ON s.product_subcategory_id = p.product_subcategory_id
JOIN bronze.product_category c
ON c.product_category_id = s.product_category_idDROP MATERIALIZED LAKE VIEW IF EXISTS silver.sales;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS silver.sales
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT
d.sales_order_id,
d.sales_order_detail_id,
d.sales_detail_item,
d.items_per_order,
h.order_date,
h.ship_date,
h.due_date,
h.customer_id,
d.product_id,
d.order_qty,
d.unit_price,
d.percentage_discount,
c.standard_cost AS unit_cost
FROM bronze.sales_order_detail d
JOIN bronze.sales_order_header h
ON h.sales_order_id = d.sales_order_id
JOIN bronze.product_cost_history c
ON c.product_id = d.product_id AND
h.order_date >= c.start_date AND
(h.order_date <= c.end_date OR c.is_active = 1)
DROP MATERIALIZED LAKE VIEW IF EXISTS silver.tax_and_freight;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS silver.tax_and_freight
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT
*
FROM bronze.sales_order_headerDROP MATERIALIZED LAKE VIEW IF EXISTS gold.fact_tax_and_freight;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.fact_tax_and_freight
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT * FROM silver.tax_and_freightDROP MATERIALIZED LAKE VIEW IF EXISTS gold.fact_sales;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.fact_sales
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT * FROM silver.salesDROP MATERIALIZED LAKE VIEW IF EXISTS gold.dim_customer;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.dim_customer
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT * FROM silver.customerDROP MATERIALIZED LAKE VIEW IF EXISTS gold.dim_product;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.dim_product
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT * FROM silver.productDROP MATERIALIZED LAKE VIEW IF EXISTS gold.aux_sales_order;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.aux_sales_order
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT DISTINCT sales_order_id FROM silver.salesDROP MATERIALIZED LAKE VIEW IF EXISTS gold.dim_date;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.dim_date
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT
d as date,
year(d) AS year,
month(d) AS month,
element_at(
array('Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec'),
month(d)
) AS month_name,
day(d) AS day
FROM (
SELECT explode(
sequence(
to_date('2022-01-01'),
to_date(concat(year(current_date()), '-12-31')),
interval 1 day
)
) AS d
) t
ORDER BY d;
DROP MATERIALIZED LAKE VIEW IF EXISTS gold.dim_date;
CREATE MATERIALIZED LAKE VIEW IF NOT EXISTS gold.dim_date
TBLPROPERTIES (delta.enableChangeDataFeed = true)
AS
SELECT
d as date,
year(d) AS year,
month(d) AS month,
element_at(
array('Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec'),
month(d)
) AS month_name,
day(d) AS day
FROM (
SELECT explode(
sequence(
to_date('2022-01-01'),
to_date(concat(year(current_date()), '-12-31')),
interval 1 day
)
) AS d
) t
ORDER BY d;
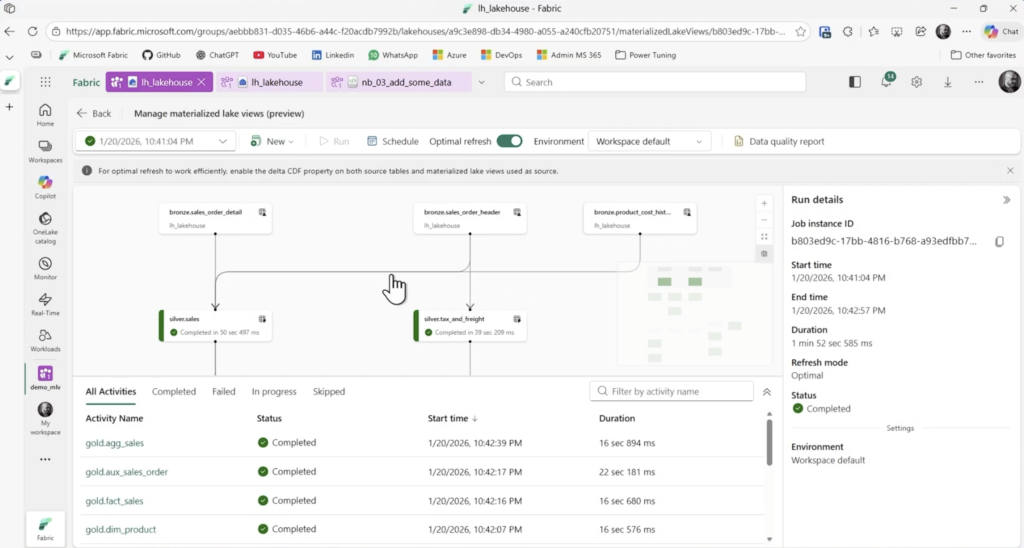
Execute o notebook. As MLVs são criadas. Volte para a área de gerencia da MLVs no Lakehouse e verifique a linhagem que é formada.
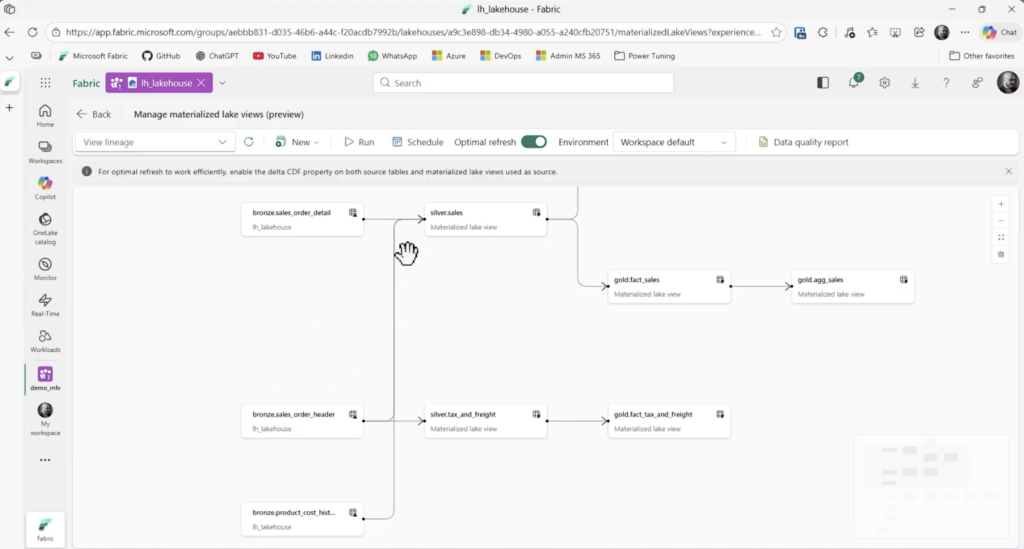
Essa visão demonstra a linhagem dos dados o que interfere na atualização das MLVs. O próprio recurso consegue definir as interdependências das tabelas, logo executa o processo de forma sequencial lógica. Primeiro executa o processo da Silver e na sequencia o da Gold. Se ainda existir tabelas agregadas como nesta imagem gold.agg_sales todas as outras tabelas irão efetuar o refresh primeiro e somente no final ela será processada. Esta definição é feita de forma automátia e autonôma.
Além disso, o Optimal Refresh decide qual método irá atualizar determinadas tabelas: Full, Incremental ou NoRefresh quando não tem dados novos na tabela de origem. Muito legal não eh?
Clique em Run e confira neste novo refresh a sequencia de atualização entre as tabelas.
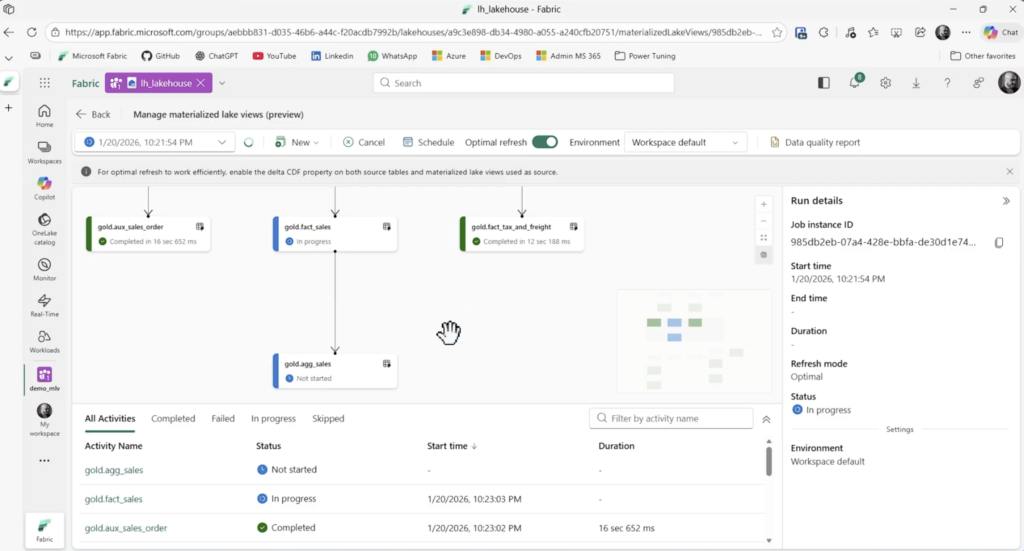
Para conferir as execuções dos refreshes você pode voltar para o lakehouse e ir até o SQL analytics endpoint e executar a query abaixo que também está no material do download.
WITH last_refresh AS (
SELECT Namespace, MLVName, RefreshTimestamp, RefreshPolicy,
TotalRowsProcessed, TotalRowsDropped,
ROW_NUMBER () OVER (
PARTITION BY MLVName
ORDER BY RefreshTimestamp DESC
) AS rn
FROM dbo.sys_dq_metrics
)
SELECT Namespace, MLVName, RefreshTimestamp, RefreshPolicy,
TotalRowsProcessed, TotalRowsDropped FROM last_refresh
WHERE rn=1
Esta query traz o último refresh para cada MLV juntamente com as informações do horário da ;ultima atualização, o tipo de refresh, full incremental ou noRefresh e as linhas processadas.
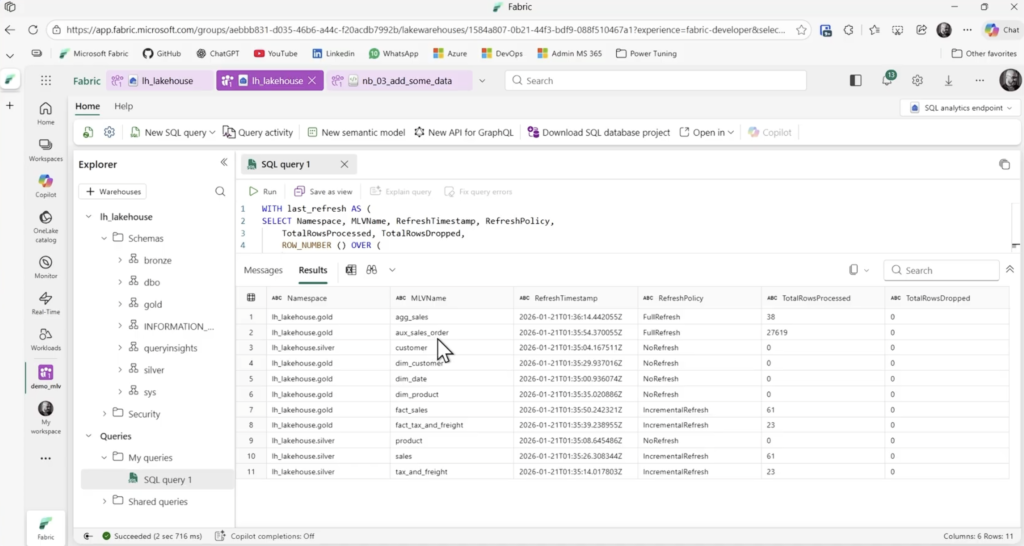
Volte ao lakehouse e abra o notebook existente nb_03_add_some_data
Este notebook acrescenta novos dados de 3 dias da base.
A ideia é rodar este notebook para cada data, uma de cada vez, na sequencia efetuar o refresh nas MLVs e checar o coportamento no SQL Endpoint para cada uma das três datas disponíveis.
Execute o processo inteiro para primeira data, substitua o dia e rode novamente com a nova data.
day = "15" # Available: 15, 16, 17from pyspark.sql.types import (
StructType, StructField, IntegerType, StringType,
DateType, DoubleType, ShortType, DecimalType
)
# sales_order_detail
schema = StructType([
StructField("sales_order_id", IntegerType(), True),
StructField("sales_order_detail_id", IntegerType(), True),
StructField("sales_detail_item", IntegerType(), True),
StructField("items_per_order", IntegerType(), True),
StructField("order_qty", ShortType(), True),
StructField("product_id", IntegerType(), True),
StructField("unit_price", DecimalType(19, 4), True),
StructField("percentage_discount", DecimalType(19, 4), True),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load(f"Files/raw/sales_order_detail_2026-01-{day}.csv")
)
df.write \
.mode("append") \
.saveAsTable("bronze.sales_order_detail")
print(f"{df.count()} new rows written in table bronze.sales_order_detail")# sales_order_header
schema = StructType([
StructField("sales_order_id", IntegerType(), False),
StructField("order_date", DateType(), True),
StructField("ship_date", DateType(), True),
StructField("due_date", DateType(), True),
StructField("customer_id", IntegerType(), False),
StructField("tax_amount", DecimalType(19, 4), False),
StructField("freight", DecimalType(19, 4), False),
])
df = (
spark.read.format("csv")
.option("header", True)
.option("delimiter", ";")
.schema(schema)
.load(f"Files/raw/sales_order_header_2026-01-{day}.csv")
)
df.write \
.mode("append") \
.saveAsTable("bronze.sales_order_header")
print(f"{df.count()} new rows written in table bronze.sales_order_header")Além das funcionalidades demonstradas ainda é possível agendar as atualizações diárias, horárias, mensais assim como todos artefatos e também é possível configurar o environment do Spark.
As vistas do lago materializadas nesta demo mostraram-se promissores recursos para a stack de engenharia de dados moderna, facilitando inclusive a migração de projetos com abordagem semelhante com views mas que por venturar tem problemas com perfomance. Uma view materializada pode ser usada como uma fonte de modelos semânticos em Direct Lake, modo que elimina a necessidade de refresh do modelo e que possui ótima experiência no front end dos relatórios.
Este artigo também está disponível em vídeo aqui.
Confira a documentação oficial.
Me siga nas redes sociais abaixo, um forte abraço e até a próxima!